# fetch 请求下载文件
先来看一下最终封装的 fetch 下载资源的代码:
export const downloadFileByFetch = async (url: string, options: IReqOptions) => {
const { headers, data, timeout = 200000 } = options;
const controller = new AbortController();
const signal = controller.signal;
const timeoutId = setTimeout(() => {
controller.abort();
}, timeout);
try {
const timestamp = Date.now();
const params = new URLSearchParams({ ...data, t: timestamp });
const reqUrl = `${url}?${params}`;
const response = await fetch(reqUrl, {
method: 'GET',
headers: { ...headers },
signal,
});
if (!response.ok) {
return Promise.reject(response.statusText);
}
// 业务类代码:如果资源无法下载,就返回一个 json 形式的数据 type。这样能第一时间获取到不能下载服务端原因。
const contentType = response.headers.get('content-type');
if ((contentType?.indexOf('application/json') as number) > -1) {
const res = await response.json();
return Promise.reject(res.message);
}
try {
// 通过 content-disposition 属性来获取文件的处理方式
const regRes = /filename=\"(.*)\"/.exec(
response.headers.get('content-disposition') || ''
);
const filename = regRes ? regRes[1] : '';
// 将响应转成 blob 格式的 promise 对象
const blobFile = await response.blob();
createDownload(blobFile, filename);
} catch (error) {
return Promise.reject('文件格式转换失败');
}
} catch (error: any) {
const message =
error.message === 'The user aborted a request.'
? '服务请求超时,请稍后重试'
: '下载失败,请稍后再重试。';
return Promise.reject(message);
} finally {
clearTimeout(timeoutId);
}
};
const createDownload = (blobFile: Blob, filename: string) => {
// 兼容低版本浏览器
if ((navigator as any).msSaveBlob) {
(window.navigator as any).msSaveBlob(blobFile, filename);
return;
}
const blobUrl = URL.createObjectURL(blobFile);
const aDom = document.createElement('a');
aDom.setAttribute('download', filename);
aDom.setAttribute('href', blobUrl);
document.body.appendChild(aDom);
aDom.click();
const timer = setTimeout(() => {
document.body.removeChild(aDom);
window.URL.revokeObjectURL(blobUrl);
clearTimeout(timer);
}, 2000); // 延迟2秒后移除a标签
// callback && callback();
// successCb && successCb();
};
上述代码的下载文件的流程大概有几个过程:
- fetch 方法请求资源接口,得到一个响应结果 response。
- response 通过调用
response.blob()方法获取一个 response 流并将把它读取出来。返回一个 promise 形式的 blob 对象。 - 通过
URL.createObjectURL将 blob 对象转成一个 url - 使用 a 标签配置转成 url 进行下载功能的处理。
所以,整个过程关联了以下一些问题:
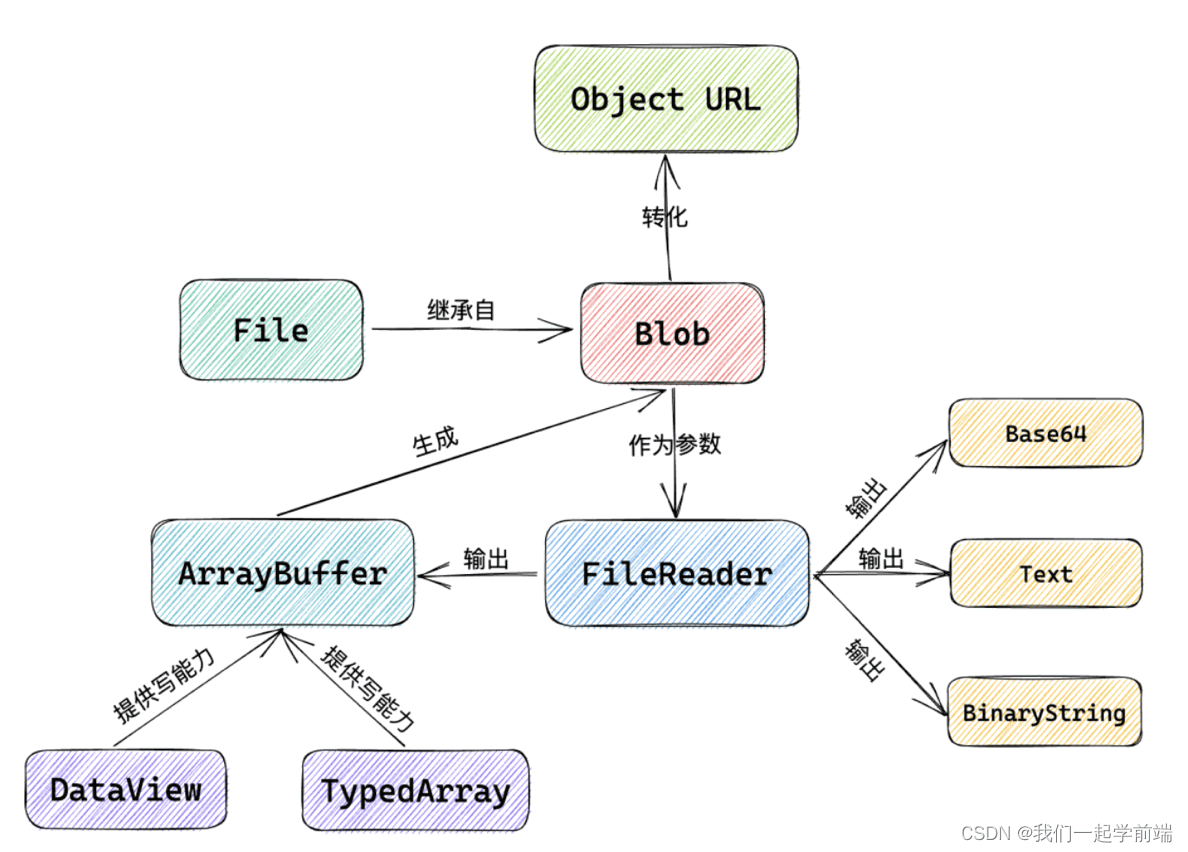
- Blob 对象是什么?
- 为什么把 response 转成 blob 对象后就可以下载了?
URL.createObjectURL方法是什么,它把 blob 对象转成什么样的 url 了?
# Blob 对象
MDN 解释
Blob 对象表示一个不可变、原始数据的类文件对象。它的数据可以按文本或者二进制的格式进行读取。也可以转换成 ReadableStream 来用于数据操作。
Blob 对象全称是 binary large object,即二进制大型对象。
它本质上是 js 中的一种对象,里面可以存储大量的二进制编码格式的数据。所以,根据名称来理解,它就是用来表示二进制数据内容的。
它的数据可以来源于文件,因此 Blob 可以用来读写文件,比如读写一个图片文件的内容。
Blob 对象的数据是不可修改的。 可以通过 FileReader 来进行读取,或者通过 Response 对象的方式来进行读取。
# 创建 Blob 对象
使用 Blob 构造函数来创建 new Blob(array, options)。
参数 1:
array由 ArrayBuffer、ArrayBufferView、Blob、DOMString 等对象构成,这些都可以被放进 Blob 中。参数 2:
通过
endings来指定包含行结束符\n的字符串如何被写入,默认是transparent,该配置不常用。通过
type指定放进 blob 中的参数 MIME 类型。所谓 MIME 类型,全称是 Multipurpose Internet Mail Extension 多用途互联网邮件扩展。
互联网上使用的每个资源都有一个媒体类型,也被称为 MIME 类型。这些信息对于服务器和客户端之间的通讯是必要的。 浏览器需要知道发送给它的资源的媒体类型,以便它能够正确地处理它们。 服务器也是如此。
type 类型有以下内容:
MIME 类型 描述 text/plain 纯文本文档 text/html HTML 文档 text/javascript js 文件 text/css css 文件 application/json JSON 文件 application/pdf PDF 文件 application/xml XML 文件 image/jpeg JPEG 图片 image/png PNG 图片 image/gif GIF 图像 image/svg+xml SVG 图像 audio/mpeg MP3 文件 video/mpeg MP4 文件
# 创建一个字符串文本类型的 blob
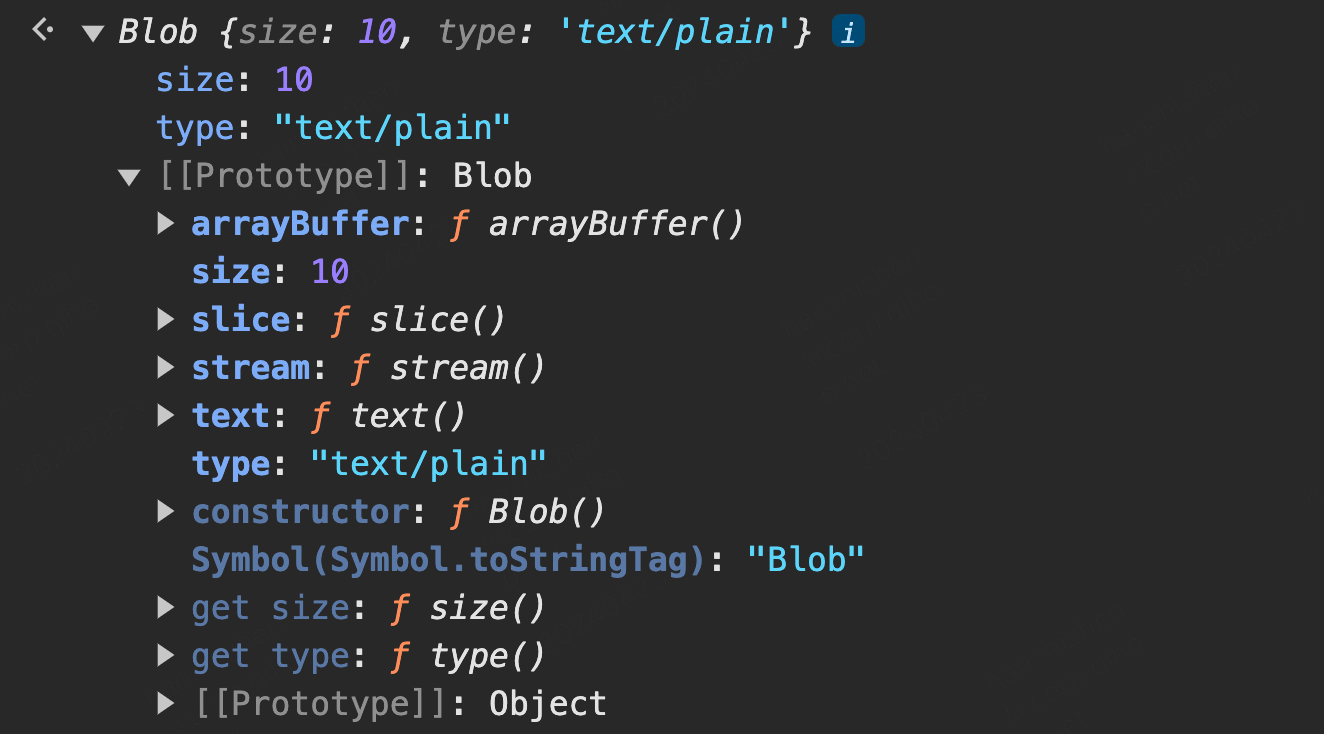
const blob = new Blob(["helloworld"], { type: "text/plain" });
得到的结构如下,blob 对象有 10 个字节,MIME 类型是传入的 text/plain 形式的。
# Blob 对象的属性
- Blob.size 获取包含数据的大小,只读。
- Blob.type 获取数据 MIME 类型的字符串,位置类型是空字符串,只读。
# Blob 对象的方法
Blob.slice([start[, end[, contentType]]]) ,返回包含指定范围数据的新 Blob 对象;
Blob.stream() ,返回一个能够读取 Blob 数据内容的 ReadableStream ;
Blob.text() ,返回 Promise ,获得包含 Blob 所有数据的 UTF-8 格式 USVString ;
Blob.arrayBuffer() ,返回 Promise ,获得包含 Blob 所有数据的二进制格式 ArrayBuffer ;
# Blob 对象的分片
Blob 分片被用到最多的地方是就是文件的分片上传。
Blob 对象内置了一个 slice 方法来对 blob 对象进行分片处理。
slice 方法有三个参数:
start: 设置切片的起点,即切片的开始位置,默认值 0,这意味着切片应该从第一个字节开始。
end: 设置切片的结束点,会对该位置之前的数据进行切片。即 end 值不被包含在当次切片内容中,默认是 blob.size。
contentType: 设置新的 blob 的 MIME 类型。如果省略 type, 则 type 就是一个空字符串。
slice 方法返回的是一个新的 Blob 对象。它包含了调用 slice 方法的原始 Blob 对象数据指定的范围子集。最重要的是,原始 blob 对象并没有被改变。
const blob = new Blob(["helloworld"], { type: "text/plain" });
const blob1 = blob.slice(0, 5);
console.log("blob1>", blob1);
const blob2 = blob.slice(0, 5, "text/plian");
console.log("blob2>", blob2);

# File 对象
说起 Blob 对象,大多能看到两句话:
它的数据可以来源于文件,因此 Blob 可以用来读写文件。
File 对象的接口基于 Blob,它继承了 blob 的功能并进行了扩展,以支持用户系统上的文件操作。
所以,文件操作是 Blob 对象的典型使用场景。
为此,JS 提供了我们常见的 File 对象,File 对象包含了 Blob 对象的全部功能,同时增加了一些新的属性,如 name 和 lastModifiedDate。
# input 标签文件上传获取
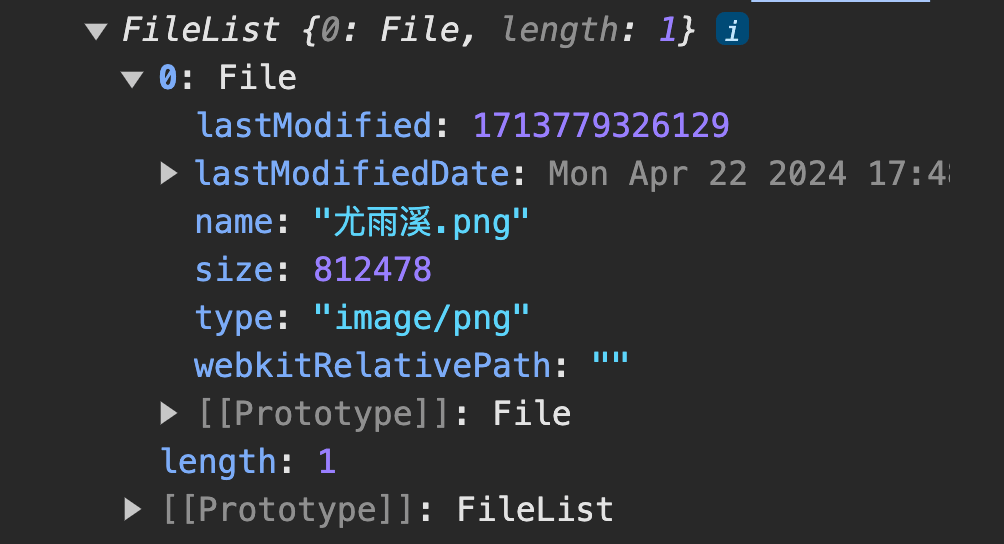
我们通常使用 input 文件选择器给用户提供选择文件的功能,通过浏览器执行 onchange 方法获取 File 对象数组。
<input type="file" name="files" accept="image/*" id="input-file" />
const fileDom = document.querySelector("#input-file");
fileDom.addEventListener(
"change",
function (e) {
console.log(e);
console.log(e.target.files);
},
false
);
# 通过拖拽文件来获取
<div id="drag"></div>
<style type="text/css">
#drag {
width: 300px;
height: 300px;
border: 1px solid #ccc;
}
</style>
<script type="text/javascript">
const dragDom = document.querySelector("#drag");
dragDom.ondragover = function (e) {
e.preventDefault();
};
dragDom.ondrop = function (e) {
e.preventDefault();
let files = e.dataTransfer.files;
console.log(files);
};
</script>
# FileReader
通过 console.log 打印 blob 对象时,可以看到。blob 对象只能看到 size 和 type 类型。无法直接读取它的内容。
FileReader 是用来读取 Blob 对象的内容的。
# 读取方式
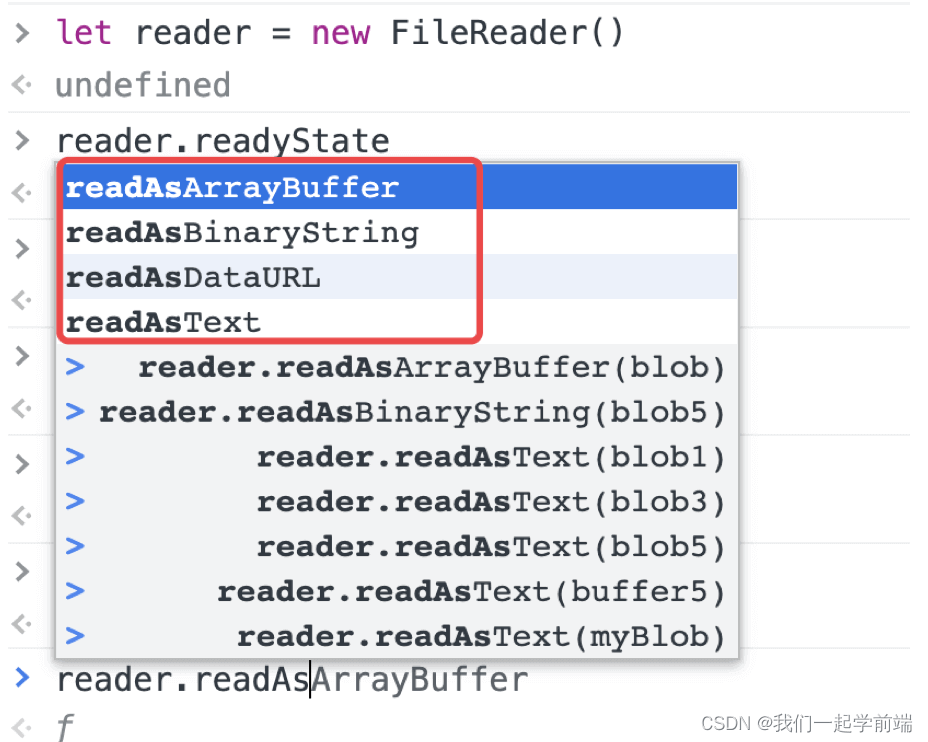
它有以下几个读取的方式:
readAsArrayBuffer 读取指定 Blob 中的内容,完成之后,result 属性中保存的是被读取文件的
ArrayBuffer数据对象。readAsBinaryString 读取指定 Blob 中的内容,完成之后,result 属性中保存的是被读取文件的原始二进制数据。
readAsDataURL 读取指定 Blob 中的内容,完成之后,result 属性中将包含一个
data:URL格式的 base64 字符串以表示所读取的文件的内容。readAsText 读取指定 Blob 中的内容,完成之后,result 属性中将包含一个字符串以表示所读取的文件内容。
# readAsDataURL
将内容读取为 base64 字符串的形式,主要针对图片等内容上传时的操作处理。
<input type="file" name="files" accept="image/*" multiple id="input-file" />
<img src="" id="showImg" style="display: block;" />
<script type="text/javascript">
const fileDom = document.querySelector("#input-file");
fileDom.addEventListener(
"change",
function (e) {
console.log(e.target.files);
const reader = new FileReader();
// 将 File 的内容以base64的方式读取出来
reader.readAsDataURL(e.target.files[0]);
reader.onload = function (event) {
console.log(event.target.result);
const imgDom = document.querySelector("#showImg");
imgDom.src = event.target.result;
imgDom.style.width = "100px";
imgDom.style.height = "100px";
};
},
false
);
</script>
# readAsText
将内容读取成字符串的形式。
const blob = new Blob(["helloworld"], { type: "text/plain" });
const reader = new FileReader();
reader.readAsText(blob);
reader.result; // 就是 helloworld
# URL.createObjectURL(object)
参数 object 的类型就是 File 对象、Blob 对象或者是 MediaSource 对象。
返回值 是一个包含了参数对象的 URL string,这个 URL 可以用于指定源 object 的内容。
注意几个问题:
返回的 URL 的生命周期和创建它的窗口中的 document 是互相绑定的,也就是说当浏览器卸载 document 的时候,会自动释它们。但还是建议在合适的时机主动释放掉它们。
每次调用 createObjectURL() 方法时,都会创建一个新的 URL 对象,即使你已经用相同的对象作为参数创建过。所以,当不再需要这些 URL 对象时,每个对象必须通过调用 URL.revokeObjectURL() 方法来释放。
# Content-disposition
Content-disposition 是 MIME(电子邮件) 协议的扩展,MIME 协议指示 MIME 用户代理如何显示附加的文件。
它作为对下载文件的一个标识字段,有两种类型:inline 和 attachment 。
- inline (默认值):将文件内容直接显示在页面;
- attachment:弹出对话框让用户下载。
当 Internet Explorer 接收到头时,它会激活文件下载对话框,它的文件名框自动填充了头中指定的文件名。(请注意,这是设计导致的;无法使用此功能将文档保存到用户的计算机上,而不向用户询问保存位置。)
服务端向客户端游览器发送文件时,如果是浏览器支持的文件类型,一般会默认使用浏览器打开,比如 txt、jpg 等,会直接在浏览器中显示,如果需要提示用户保存,就要利用 Content-Disposition 进行一下处理,关键在于一定要加上 attachment:
Response.AppendHeader(“Content-Disposition”,“attachment;filename=FileName.txt”);
备注:这样浏览器会提示保存还是打开,即使选择打开,也会使用相关联的程序比如记事本打开,而不是 IE 直接打开了。
# 在页面内打开文件
response.setHeader("Content-Type","text/plain");
response.addHeader("Content-Disposition",`inline;
filename="+new String(filename.getBytes(),"utf-8`));
response.addHeader("Content-Length",""+file.length());
# 弹出保存文件弹窗
response.setHeader("Content-Type","text/plain");
response.addHeader("Content-Disposition",`attachment;
filename="+new String(filename.getBytes(),"utf-8`));
response.addHeader("Content-Length",""+file.length());
# 总结