# 闭包
# 作用域
TIP
ES6 之前,javascript 中的作用域只有两个:函数作用域和全局作用域
ES6 之后,const 与 let 声明变量的方式,出现了块级作用域,同时衍生出一个“暂存性死区”。
关于暂存性死区,需要特别注意的是参数传递时的情况。
function fn(arg1 = arg2, arg2) {
console.log("arg1", arg1, "arg2", arg2);
}
// 正常传参数
fn("arg1", "arg2"); // 返回 arg1, arg2
// 第一个参数不传递的时候
fn(undefined, "arg2");
// 释解:传递undefined,表示 arg1 取默认值 arg2。但是执行 arg1 = arg2 时,arg2还未声明,其实是一个暂存性死区。
// 所以会报错:arg2 is not defined
// undefined 和 null 又不同
fn(null, "arg2"); // 返回 null, arg2
# 执行上下文
执行上下文就是当前代码的执行环境/作用域,和作用域链相辅相成。有了作用域链,才有了执行上下文的一部分。
执行 js 代码有两个阶段:1. 代码预编译阶段 2. 代码执行阶段
代码编译阶段
这个编译与传统的编译意义不同,不涉及那种分词、解析、代码生成的过程。js 是一门解释型语言,编译一行,执行一行。但是代码执行之前,js 的引擎会提前做一些“预准备的工作”。
语法分析确认无误后,预编译阶段对 js 代码中的变量的内存空间进行分配,变量提升就在该阶段。有 3 个注意点:
预编译阶段进行变量声明
预编译阶段进行了变量提升,但是变量值为 undefined
预编译阶段对所有的非表达式函数声明进行了提升。
// part1
function bar() {
console.log("bar1");
}
// part2
var bar = function () {
console.log("bar2");
};
bar();
无论 part1 和 part2 谁在前谁在后,结果都是一样的 bar2:
- 首先是 var bar 变量提升,但是 bar 是 undefined
- 然后函数声明 function bar 提升,存在了一个 bar 函数
- bar 被复制给了 console.log('bar2') 的函数
- 最后函数执行得到 bar2
# 调用栈
所谓调用栈,就是一些列函数串联调用,如下述列子:
function foo1() {
foo2();
}
function foo2() {
foo3();
}
function foo3() {
foo4();
}
function foo4() {
console.log("foo4");
}
foo1();
执行构成中:foo1 先入栈,调用了 foo2,foo2 跟着入栈,以此类推。直到 foo4 执行结束,foo4 出栈,foo3 再出栈,以此类推。整个过程遵循,先进后出。
正常情况下,函数执行结束并出栈,函数内的局部变量在下一个垃圾回收(CG)节点会被回收,该函数对应的执行上下文会被销毁,这也是我们无法在外界访问函数内定义的变量的原因。
也就是说,只有函数执行时,相关函数才可以访问相关变量,该变量会在预编译阶段被创建,在执行阶段被激活,在函数执行结束后,其相关上下文会被销毁。
# 闭包来了
形式化定义
函数嵌套函数时,内层函数引用了外层函数作用域下的变量,并且内层函数在全局作用域下可以访问,进而形成了闭包。
function numGenerator() {
let num = 1;
num++;
return () => {
console.log(num);
};
}
var getNum = numGenerator();
getNum();
numGenerator 函数中创建了一个变量 num,接着返回打印 num 值的匿名函数,这个函数引用了变量 num,使得在外部可以通过调用 getNum 方法访问变量 num,因此 numGenerator 执行完毕后,即使相关调用栈出栈后,变量 num 也不会消失,仍然有机会被外界访问。
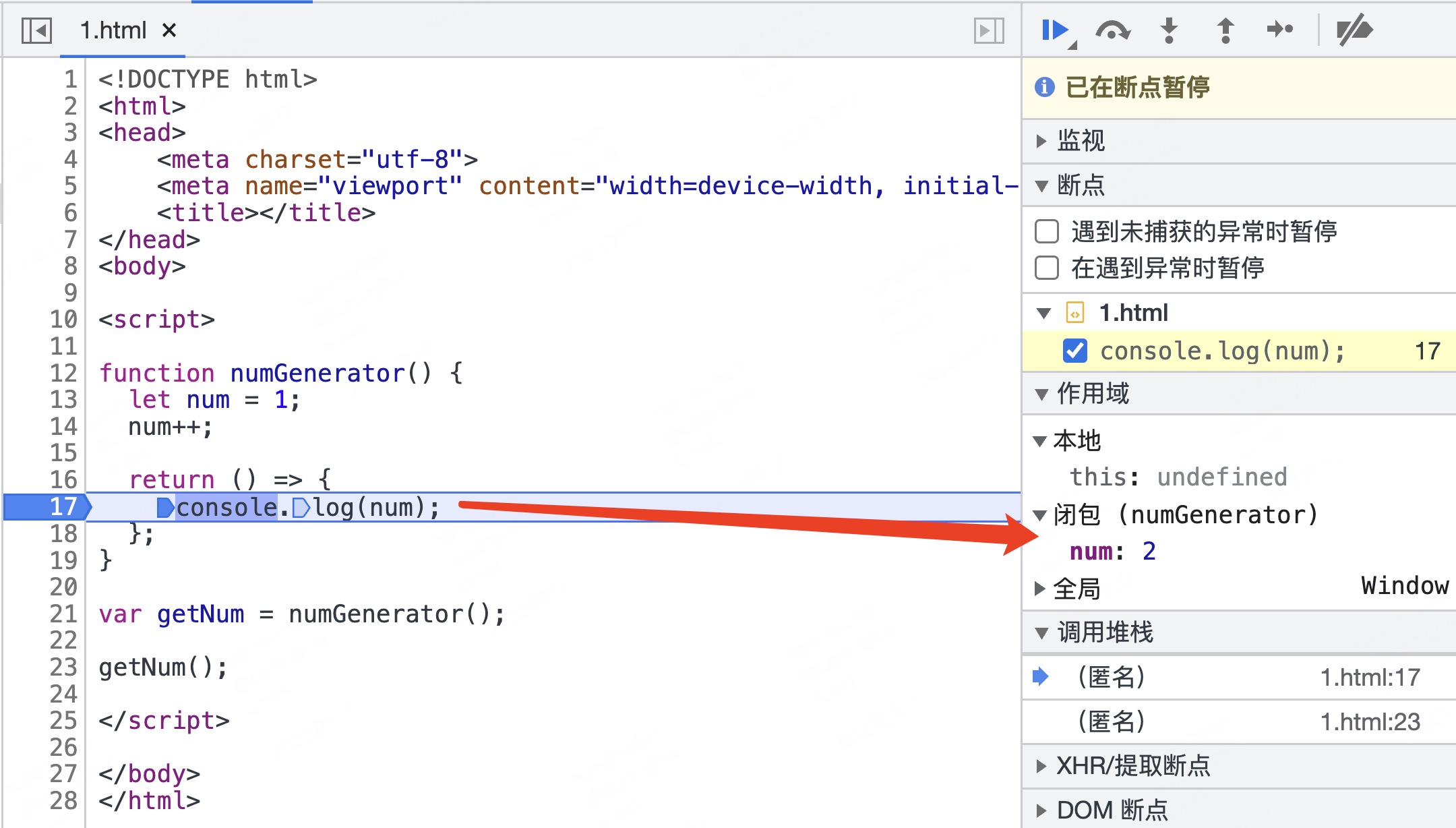
正常情况下,外界无法访问函数内部的变量,函数执行结束后,上下文立即被销毁。但是在外层函数中,返回了另一个函数,并且这个返回的函数使用了外层函数内的变量,那么外界便能够通过这个返回的函数获取原函数(外层函数)内部的变量,这就是闭包的基本原理。
# 内存管理
内存管理指的是内存生命周期的管理,分配内存、读写内存、释放内存
var foo = "bar"; // 分配内存
alert(foo); // 读写内存
foo = null; // 释放内存
内存空间分为栈空间和堆空间:
TIP
- 栈空间:由操作系统自动分配释放,存放函数的参数值、局部变量的值等,其操作方式类似于数据结构中的栈
- 堆空间:一般由开发者分配释放,这一部分需要考虑垃圾回收的问题
在 js 中,不考虑 ES6 后的新数据类型,基本数据类型存放在栈空间中,占用固定大小的内存空间;引用类型保存在堆空间中,内存空间大小不固定。
基本数据类型:undefined、string、boolean、null、number,在栈空间
引用类型:object、array、function 在堆空间中
内存泄漏举例
var element = document.getElementById("element");
element.mark = "marked";
// 溢出 dom 节点
function remove() {
element.parentNode.removeChild(element);
}
remove();
// 完善的做法
// element = null
上述代码中,虽然最终的结果移除了 element 节点,但是变量 element 仍然存在,该节点占用的内存并没有被释放。 完善的做法是 将 element = null
# 实战例题
# 例题 1
const foo = (function() {
var v = 0
return () => {
return v ++
}
}())
for(let i=0 i<10; i++) {
foo()
}
console.log(foo())
首先,foo 是一个立即执行函数,如果 console.log(foo) 得到的是
() => {
return v++;
};
所以在循环执行 foo 函数时,自由变量 i 执行了 10 次,v 也自增了 10 次。所以最后再打印就是 10。
# 例题 2
const foo = () => {
var arr = [];
var i;
for (i = 0; i < 10; i++) {
arr[i] = function () {
console.log(i);
};
}
return arr[0];
};
foo()();
foo() 执行后得到的是 arr[0], 而 arr[0] 也是一个函数,它内部的 i 是 10,所以答案是 10
# 例题 3
var fn = null;
const foo = () => {
var a = 2;
function innerFoo() {
console.log(a);
}
fn = innerFoo;
};
const bar = () => {
fn();
};
foo(); // 2
bar(); // 2
正常来说,根据函数调用栈,foo 函数执行结束后,其执行环境生命周期会结束,占用的内存被垃圾收集器释放,上下文消失。
但是通过将 innerFoo 函数赋值给全局变量 fn, foo 的变量对象 a 也会被保存下来。
所以,函数 fn 在函数 bar 内部执行,依然可以访问这个被保留下来的变量对象,输出结果为 2.